

No matter if you are building a brand new website, developing a theme or plugin, or setting up advanced continuous integration and deployment strategies, you will be working with code.
Under every website, there is code being executed — whether you’re using WordPress, WooCommerce, Drupal, Magento, NextJS, or even hand-coded HTML. There are sets of files needed to make each page render and display content to the world.
What you quickly discover is that you need a way to track code changes over time. You need to know what changes are in the most current version of any file, and who made each change.
This is where Git comes in. Keep reading to learn about Git, working with remote Git repositories, and more.
Understanding Git
Git is a version control system that allows developers, and anyone else who is working with files, to easily create and store versions of their changes, see a history of those changes, and share those changes between devices and systems, all while providing a way to undo those changes in case something goes wrong.
A Brief History
Way back in 2005, a team of developers was creating a project called Linux, the free and open source operating system. They needed a way to easily communicate changes among hundreds of contributors. Originally, they had been passing around individual patches that contained the updated code, but this proved problematic on many fronts, especially when determining what was the “true” and latest version of any particular set of changes.
Frustrated by these issues, the Linux project led Linus Torvald to implement a rather novel idea for a project to share the whole codebase between developers and take "snapshots" of their changes, called commits, which could be shared and merged with any other copy of the code, anywhere in the world. Immediately this helped with communication, as all project changes could be viewed as a single history.
That method for capturing these snapshots is Git, which quickly took on a life of its own and has been developed independently of the Linux project ever since.
A Graph of Changes
Conceptually, you can think of Git as a graph of nodes, where each node is a snapshot of the whole project at a moment in time. The Git book, over on git-scm.com outlines the structure of a snapshot.
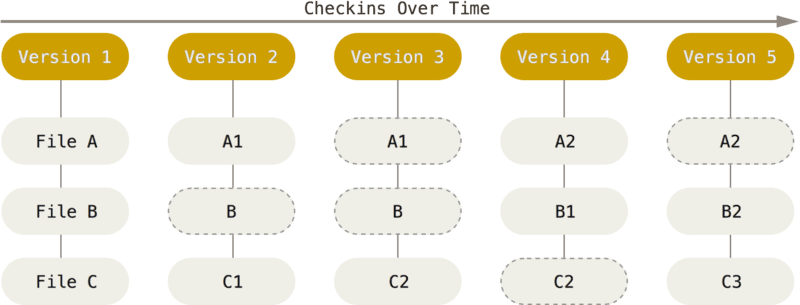
This chain of snapshots builds a graph over time, with the most recent version in the front, or at the top of your history of changes. Each snapshot is referred to as a “commit” in Git.
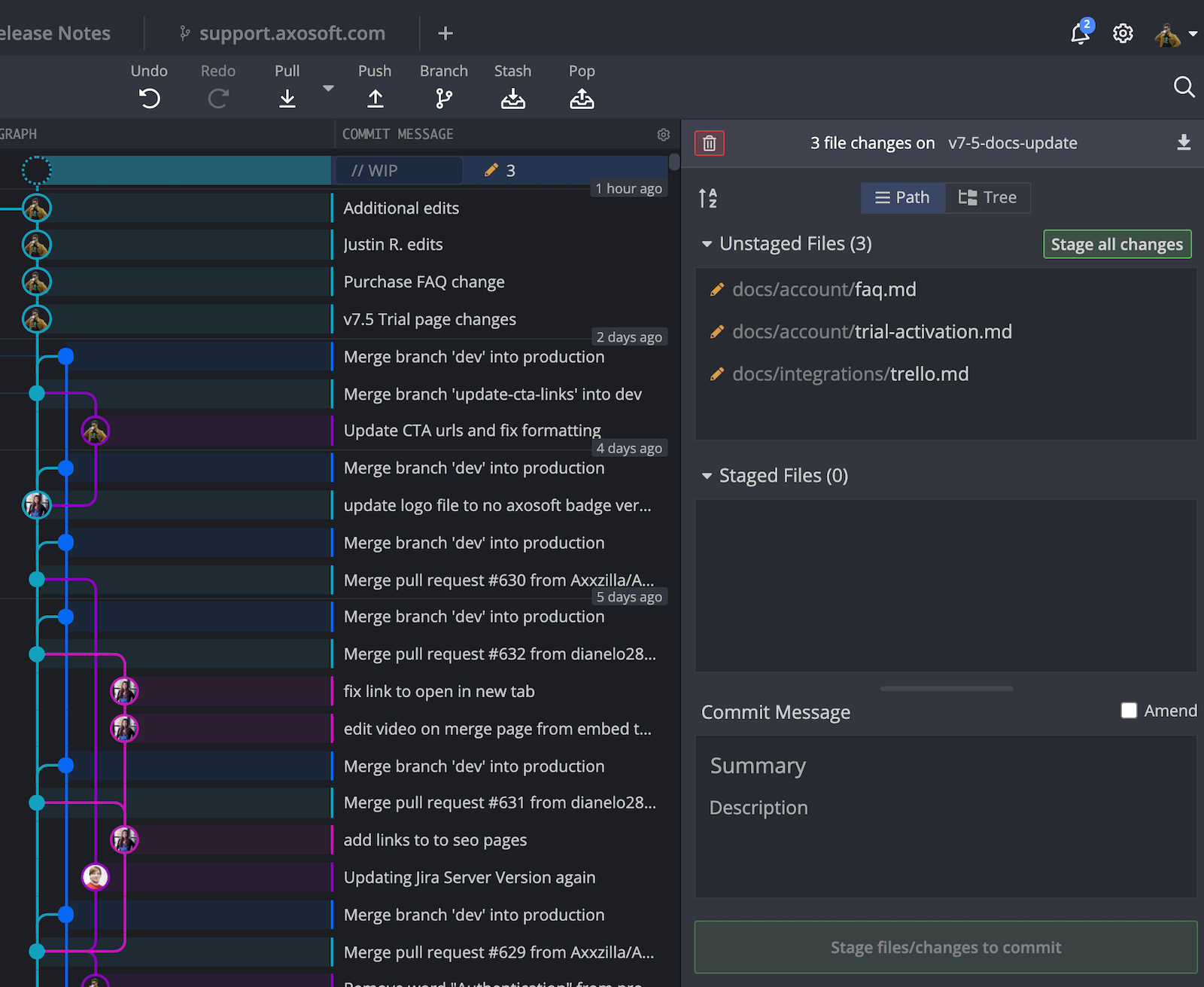
Here is a quick look at what a Git project looks like if you put the most recent change at the top of the graph. Note — this example is using the GitKraken Git GUI to visualize the graph.
Building the Git Graph
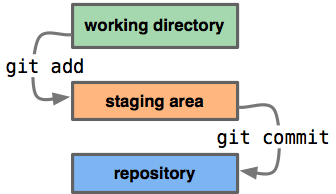
Git builds this graph of changes, also known as your Git history, through a process of committing changes. Before you can commit changes, however, you will need to specifically tell Git what you want to add to that snapshot, or commit as it is properly referred to in Git.
When working locally, all the changes you are saving in your project are in your "Working Directory." Git can see those changes, but doesn’t yet know which changes you want to commit. You will need to tell Git explicitly which changes you want to commit by using a command called “git add” to add those specific files to the “staging area” of Git.
Once you have the file changes you want to commit to the graph of project snapshots, you then can use the “Git commit” command to permanently build that snapshot onto the graph.
Moving Back in Time
One of the advantages of Git and having your entire project history available is that you can move back and undo any and all changes at any time.
If the last commit you make breaks something, or you change your mind about what you did, you can do a “Git revert” to revert the Git commit. This creates a new commit on the graph that simply undoes the changes you just made.
If you want to jump back in time and make it look like you never made a commit, you can use “Git reset” to do this.
The Power of Branching and Merging in Git
One of the most powerful features Git gives us is the ability to create parallel alternate realities. No, really.
Since you are making a graph of commits over time, you can choose to make parallel lines of commits, called branches, from any point in your history. A newly created Git branch is independent of the main history, meaning you are free to make any changes you want and it will not affect your other work. The main timeline is also a branch and is most commonly called either the “main” or “master” branch. New branches and branches other than main are commonly referred to as “feature branches.”
Once you have made the changes to your feature branch, you can apply all of the changes to the main branch by performing a Git merge.
There is a great advantage to working this way. A feature branch isolates the code changes, so if you do introduce errors, you can rest assured that the main branch is safe. Working in branches also frees up the main branch in case you need to apply an update or security fix without interrupting the ongoing development work in progress.
Git merging also allows you to pull changes from the main branch into a feature branch. This gives you the ability to make sure updates made to the main branch will still work with your proposed changes before you attempt to merge them with “main.”
If you are working with a team, a Git branching strategy can ensure that your team can test changes thoroughly before they make it to production and provide a straightforward way to manage the process.
Working With Remote Repositories in Git
One of the major goals of Git is to make it simple to share code with people throughout the world. Built into Git is the notion of a remote repository.
A Git repository is the entire project folder where you store your work and is what Git is tracking over time. Each repository can be cloned using the Git clone command, and shared an unlimited number of times, making Git very scalable.
Another aspect that makes Git very scalable is that if you change a document, you do not need to store an entirely new copy of that document. Changes are stored as little packets of information referred to as “deltas,” and only the individually modified lines of a file and a little bit of data about the change is what Git needs to store or share. Deltas are very lightweight, often just a few bytes in size. For example, if you change a single line in a 100KB document, the delta will only be 20 bytes or so.
To keep everything in line and consistent across all copies of a repository, you simply need to designate which copy, located on which computer, is the “true” copy of the project, and then make sure your commits make it to that copy.
This works the other way as well. When collaborating with others, you can pull their changes into your local copy of the repository to ensure your local copy of the project is up to date.
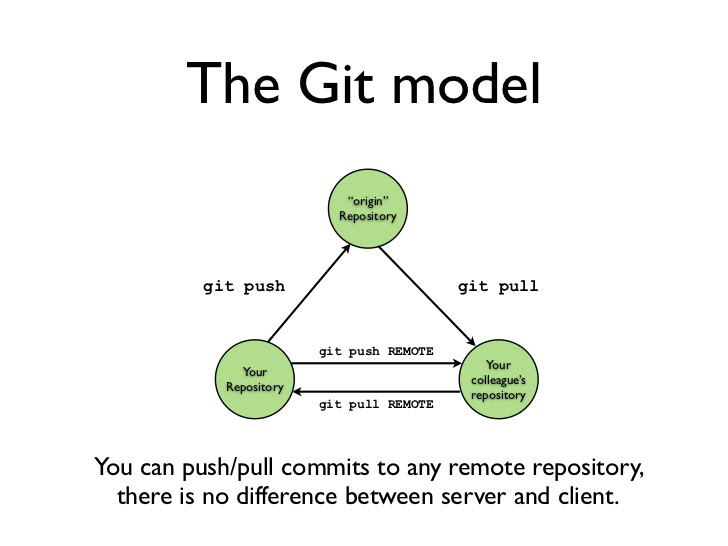
There are a number of companies that make collaborating on remote repositories extremely simple and manageable. Platforms such as GitHub, GitLab, and BitBucket offer online Git repository hosting and collaboration tools. There are many millions of Git repositories online being managed by millions of developers, and Git tracks every single source of truth, no matter how many people are collaborating.
What Not to Store in Git
Let's talk about what you probably should not do with Git. While Git is amazing at sharing code and tracking changes over time, there are some jobs that are not well suited for the model. Fortunately, Git gives us a handy way to tell it to ignore things, called a “.gitignore” file.
If a “.gitiginore” file is present, Git will check against it to see if it should be watching those items at all. Inside a “.gitiginore” you can list individual file names, entire directories, or entire types of files. For example, if you wanted to exclude all .png and .jpg files and your entire “wp-content/uploads” folder, in your “.gitiginore” files you would simply write:
*.png
*.jpg
wp-content/uploads
Why Exclude Media Files From Git?
Git stores snapshots of a project and only passes the “deltas” around. But if the file in question is a “blob” of data, like an image, video, or any other binary file, each alteration of the file will create a whole new blob of data. Git then needs to remember the state of both the old blob and the new blob, adding a lot of unnecessary size to the repository. This builds up over time, and repositories soon become unwieldy as you lose the lightweight benefits of Git.
Believe it or not, you might not want to track changes in WordPress core itself. There are a couple of reasons for this.
First, there is an old saying with any CMS: "Don't hack core!" There should be nothing you are changing in the core of WordPress that will need to be tracked. Any updates will need to come from WordPress itself and if you want an earlier version, that is easily specified when you install it. You absolutely can store an entire WordPress installation in Git, but there is not a lot of value in doing so in certain situations. You really only want to track changes to the code you are manipulating, like your custom plugins and child themes. It is a really good idea to check with your hosting provider for their advice on this topic.
Second, if you plan to contribute back to WordPress, you will find that it is actually maintained through an older version control system called SVN. This model requires a central server infrastructure and is a lot less popular compared to Git, but then again, WordPress is older than Git. Working with the SVN patching system is a little different and you should consult their documentation for more on this.
Conclusion
Hopefully, you now have a better understanding of what Git is and how it can be leveraged for working with your website's code. Git can be used for any and all files you will change over time, even if it’s not computer code.
Git refers to its target users as “knowledge workers,” an old term borrowed from IBM. For everything from notes on your desktop to recipes, to entire books, Git gives you a way to better organize your work and leave yourself a solid trail of why you made each change and when it was made.
The power of being able to go back in time and see your changes, mixed with the ability to work in unlimited parallel universes with branching and merging, makes Git an indispensable tool for anyone working on code. Git is also the primary way teams collaborate on code projects.
Git is free to use and most Git GUIs, like GitKraken have free versions. There is no reason you should not be using Git to track your work, so “Git” to it!
Related Resources
- WordPress Local Development with XAMPP

